
Kmeans&Agglomerative模型
KMEANS&Agglomerative模型
在传统的公司评估中 往往仅通过一类指标进行判定,聚类方法可以尽可能的多维度囊括公司信息,在大数据的前提下聚类法能更好的描述公司的数据相似性。KMeans算法是以距离作为相似度的评价指标,用样本点到类别中心的误差平方和作为聚类好坏的评价指标,通过迭代的方法使总体分类的误差平方和函数达到最小的聚类方法。另一方面,Agglomerative模型可以将最初将每个对象看成一个簇,然后将这些簇根据某种规则被一步步合并,就这样不断合并直到达到预设的簇类个数,这样做的好处是在Kmeans的基础上,再根据图像,将需评估的公司分成不同数量的类别,进一步描绘公司画像。
具体的,首先针对KMeans聚类,选取Fiance(融资轮次), Patent(知识产权), City(城市下沉指数),Rent(租金),Euip(舒适度), Traffic(交通便利指数),Food(餐饮方便指数)七个指标对数据进行聚类分析。为了确定最佳的类别数量,首先画出2-10之间,不同类别数量下的分数。
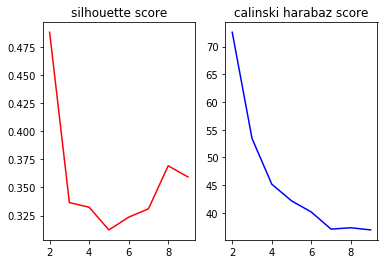
基于上图,选择将数据分为两类,最终得到silhouette_score为:0.4879961346798957, calinski_harabaz_score为:72.5849084643773
KMeans可视化:
本文收集到的数据维度较多,而人类可感知的最大维度为三维,同时高维数据经过降维后可以在低维状态下更好的显示出本质特性,故在此通过降维以实现数据可视化。
因为线性降维算法的主要问题是不相似的数据点放置在较低维度表示时,相距甚远。而PCA是线性算法,并不能很好地解释特征之间的复杂多项式关系。因此选择t-SNE算法进行降维,t-SEN是基于在邻域图上随机游走的概率分布来找到数据内的结构,可以在低维度用非线性流形表示高维数据。
得到降维后结果为:
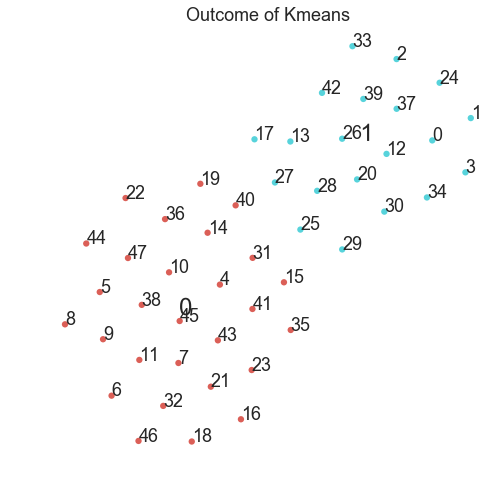
其中编号代表数据集中的不同公司。
Agglomerative可视化
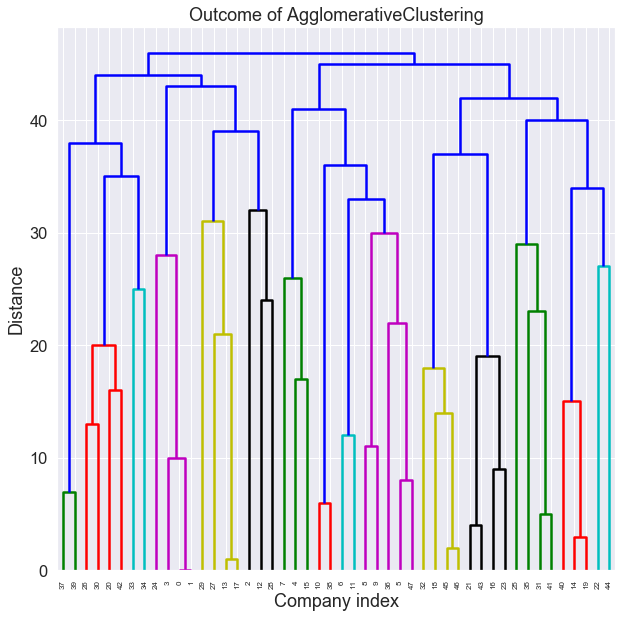
如图所示,根据不同的颜色,Agglomerative可以按照需求对所有公司进行不同程度上的聚类,从而由点到面的对公司进行从具体到通用的画像描述,最终顶层聚为两类,和Kmeans的结果保持一致。
上一篇:回归分析模型
下一篇:没有了